NucleiSeg-in-Histopathology-Images

Nuclei Segmentation in Histopathological Images with Enhanced U-Net3+
Official implementation of the paper published at MIDL 2024
Report Bug
·
Request Feature
Qualitative Performance Comparison

Quantitative Performance Comparison

Setup
- Clone the repository:
git clone https://github.com/CVPR-KIT/NucleiSeg-in-Histopathology-Images.git - Create a new environment and install the required packages:
pip install -r requirements.txt
Dataset
The dataset for this challenge was obtained by carefully annotating tissue images of several patients with tumors of different organs and who were diagnosed at multiple hospitals. This dataset was created by downloading H&E stained tissue images captured at 40x magnification from the TCGA archive. H&E staining is a routine protocol to enhance the contrast of a tissue section and is commonly used for tumor assessment (grading, staging, etc.). Given the diversity of nuclei appearances across multiple organs and patients, and the richness of staining protocols adopted at multiple hospitals, the training dataset will enable the development of robust and generalizable nuclei segmentation techniques that will work right out of the box.
Training Data
Training data containing 30 images and around 22,000 nuclear boundary annotations have been released to the public previously as a dataset article in IEEE Transactions on Medical Imaging in 2017.
Testing Data
Test set images with additional 7000 nuclear boundary annotations are available here: MoNuSeg 2018 Testing data.
Sample Data
A training sample with a segmentation mask from the training set can be seen below:
| Tissue Image | Segmentation Mask (Ground Truth) |
|---|---|
 |
 |
Conversion from Annotations
The dataset contains annotations of the nuclei, and there is a need to convert them into ground truth images for segmentation. This can be done using the xmlParser.py file.
Directory Configuration
The following structure should be followed for dataset directory configuration:
MonuSegData/
├── Test/
│ ├── GroundTruth/
│ └── TissueImages/
└── Training/
├── GroundTruth/
└── TissueImages/
Experiment Setup
All modifiable parameters related to the experiment and augmentation are present in the config.sys file. Set up all parameters here before proceeding.

Data Normalization
The images in the MoNuSeg dataset are H&E stained images that have the following properties:
- Purple for nuclei
- Pink for cytoplasmic components
For more information, refer to this guide. It is recommended to perform staining normalization before augmentation. This can be done using the stainNormalization.py file:
python auxilary/stainNormalization.py --config config.sys
Generate Metadata Files for Train and Test Images
After preparing the data, run the following code to generate metadata files for image training and testing sets:
python auxilary/dataValidity.py --config config.sys
Augmentation
- Perform Sliding Augmentation:
python slidingAug.py --config config.sysIt will create the folder “slidingAug” with sliding augmentations. The parameters can be changed in the config.sys file.
- Perform Train and Validation Split:
python auxilary/trainValsplit.py --config config.sysIt will create the folder and files for Train, Validation from the augmented folder.
- Perform Other Augmentations:
python image_augmentation.py --config config.sysIt will create augmentations on the slided images in a new folder named “augmentated”. Parameters can be changed in the config.sys file.
Train Model
After checking the dataset information in the config.sys file, run:
python main.py --config config.sys |& tee log/log-08-07.txt
The parameters can be changed as per requirement in the config.sys file. A log file is created in the log folder.
Inference / Testing
For testing or inferencing images, ensure they are in the correct format and directory information is added correctly in the config.sys file:
python train_test.py --img_dir all --expt_dir <Outputs/experiment_dir>
Results
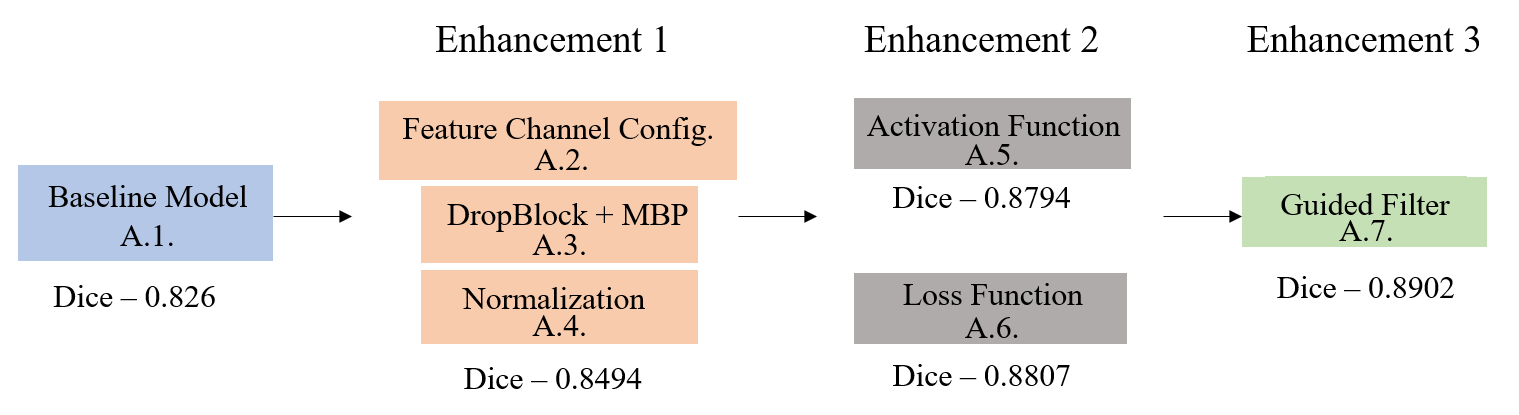
Ablation Study
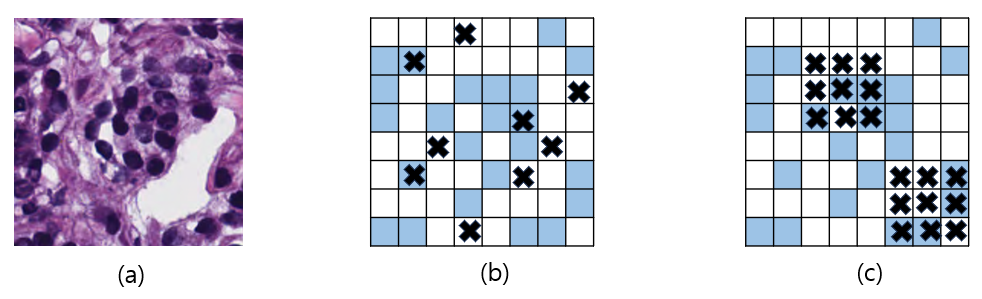
Dropblock Regularization
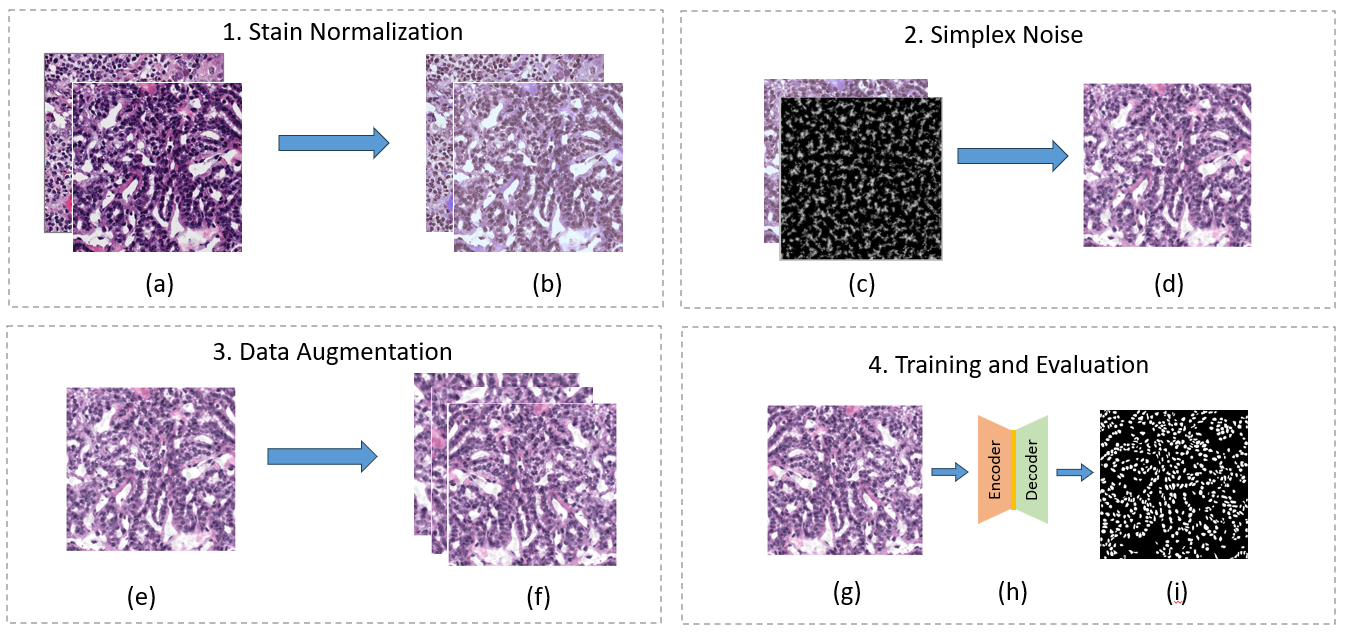
Workflow Diagram
Guided Filter

Qualitative Results

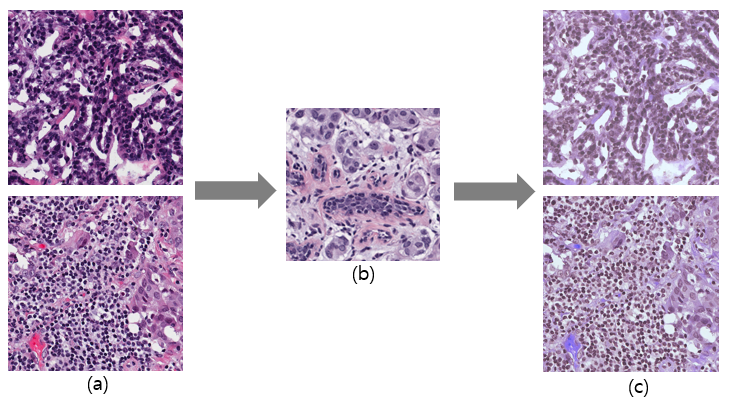
Stain Normalization
Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are greatly appreciated.
- If you have suggestions for adding or removing projects, feel free to open an issue to discuss it, or directly create a pull request after editing the README.md file with necessary changes.
- Please make sure you check your spelling and grammar.
- Create individual PRs for each suggestion.
Creating A Pull Request
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/newFeature) - Commit your Changes (
git commit -m 'Added some new feature') - Push to the Branch (
git push origin feature/newFeature) - Open a Pull Request
License
Distributed under the MIT License. See LICENSE for more information.
Authors
- Bishal Ranjan Swain - PhD Candidate at Kumoh National Institute of Technology